
 Мегаполисы мира, представляют собой динамично развивающуюся среду, где пересекаются различные аспекты жизни и бизнеса. В этой статье мы рассмотрим две, на первый взгляд, разные сферы — московские жилые комплексы и администрирование серверов. Однако, при более глубоком анализе становится очевидным, что эти области тесно связаны и взаимодействуют, создавая уникальные вызовы и возможности для инноваций.
Мегаполисы мира, представляют собой динамично развивающуюся среду, где пересекаются различные аспекты жизни и бизнеса. В этой статье мы рассмотрим две, на первый взгляд, разные сферы — московские жилые комплексы и администрирование серверов. Однако, при более глубоком анализе становится очевидным, что эти области тесно связаны и взаимодействуют, создавая уникальные вызовы и возможности для инноваций.
Современные тенденции
Московские жилые комплексы (ЖК) в последние годы претерпели значительные изменения. Современные ЖК предлагают не только комфортное жилье, но и широкий спектр услуг, включая фитнес-залы, детские площадки, магазины и даже медицинские центры. Эти комплексы стремятся создать полноценную инфраструктуру, обеспечивающую высокое качество жизни для своих жителей. (далее…)

Современные тенденции в мире серверов: как Kubernetes меняет подход к разработке для PHP
В эпоху быстрой цифровизации и постоянного роста востребованности веб-приложений, разработка стала гораздо более сложной и многогранной задачей. Сервера играют центральную роль в этом процессе, и среди технологий, формирующих будущее, выделяется Kubernetes. Эта статья объясняет, как Kubernetes влияет на работу PHP разработчиков и какие вакансии становятся актуальными на рынке труда.
Роль серверов в веб-разработке
Серверы являются основой для любого веб-приложения. Они хранят данные, обрабатывают запросы и обеспечивают взаимодействие пользователя с приложением. Веб-разработка требует надежности и масштабируемости серверной инфраструктуры. Системы, способные быстро адаптироваться к изменяющимся условиям, становятся неотъемлемой частью успеха бизнеса.
(далее…)
Горизонтальное автомасштабирование модуля
Горизонтальное автомасштабирование модуля – это автоматическое масштабирование количества реплик модуля, управляемых контроллером. Оно выполняется горизонтальным контроллером, который активируется и конфигурируется путем создания ресурса HorizontalPodAutoscaler (HPA). Данный контроллер периодически проверяет метрики модуля, вычисляет количество реплик, необходимое для соответствия целевому значению метрики, сконфигурированной в ресурсе HorizontalPodAutoscaler, и настраивает поле replicas на целевом ресурсе (развертывании Deployment, наборе реплик ReplicaSet, контроллере репликации ReplicationController или наборе модулей с внутренним состоянием StatefulSet)
Процесс автомасштабирования
Процесс автомасштабирования можно разделить на три этапа:
- получение метрик всех модулей, управляемых масштабируемым ресурсным объектом;
- расчёт количества модулей, необходимого для приведения метрик к указанному целевому значению (или близкому к нему);
- обновление поля replicas масштабируемого ресурса. Далее мы рассмотрим все три этапа
Получение метрик модуля
Автопреобразователь масштаба сам не выполняет сбор метрик модуля. Он получает метрики из другого источника. Метрики модуля и узла собираются агентом под названием cAdvisor, который выполняется в Kubelet на каждом узле, а затем агрегируется кластерным компонентом под названием Heapster. Контроллер автопреобразователя горизонтального масштаба модуля получает метрики всех модулей, запрашивая агрегатор Heapster посредством вызовов REST.

Что такое серверы VPS, VDS и Bare Metal.
Обзор технологий виртуализации и выделенных серверов в современном мире информационных технологий, выбор подходящего сервера для ваших нужд является критически важным. Серверы могут различаться как по архитектуре, производительности так и цене. В данной статье мы рассмотрим три популярных типа серверов: VPS (Virtual Private Server), VDS (Virtual Dedicated Server) и Bare Metal.
1. VPS (Virtual Private Server) — это виртуальный частный сервер, который позволяет пользователям арендовать часть физического сервера. Несмотря на то что физический сервер делится между несколькими пользователями, каждый VPS работает как отдельный сервер с собственными ресурсами и операционной системой.
Преимущества:
— Экономия: VPS обычно дешевле выделенных серверов, что делает его отличным выбором для малых и средних бизнесов.
— Настраиваемость: Пользователи имеют контроль над серверной средой, включая установку приложений и настроек.
— Изоляция: Проблемы, возникающие на одном VPS, не влияют на другие, поскольку каждый работает независимо.
Недостатки:
— Ограниченные ресурсы: Ресурсы VPS делятся с другими пользователями, что может привести к снижению производительности в пиковые часы.
— Безопасность: Несмотря на изоляцию, уровень безопасности может варьироваться в зависимости от провайдера.
2. VDS (Virtual Dedicated Server) — это разновидность VPS, но с выделением ресурсов. В то время как на VPS ресурсы могут быть динамически распределены, на VDS вы получаете гарантированные ресурсы, которые не подвержены изменению. (далее…)
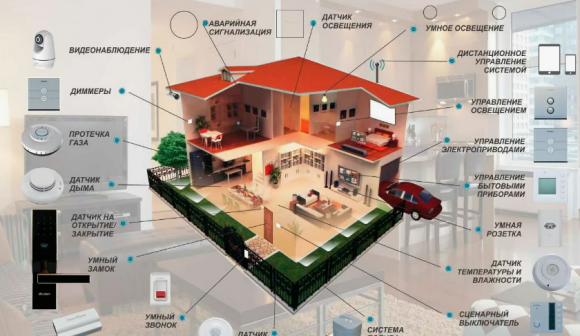
Домашняя автоматизация (англ. home automation), или умный дом (англ. smart house) — система домашних устройств, способных выполнять действия и решать определённые повседневные задачи без участия человека.
С помощью системы «умного дома» можно включать свет в любой из комнат, находясь вне дома, запускать кондиционер или тёплый пол к приходу, а также быть в курсе любых нештатных ситуаций вроде протечки в ванной комнате или задымления помещения.
Несмотря на различное исполнения, системы «умного дома» различных производителей имеют схожие черты и функционируют по единым правилам.
Каким бывает умный дом
Кто хочет автоматизировать свое жилище на высоком уровне, существуют дорогие профессиональные системы, которые должен устанавливать специализированный специалист. Однако у них есть ряд особенностей: большинство элементов имеет проводное подключение. Чтобы их запитать и соединить в цепь, сначала нужно делать разводку электрики.
«Умные модули» умеют «дружить» только друг с другом, то есть комплект должен быть одного производителя и одной серии. (далее…)
0